新着情報
YOLOv3の利用(2):UBUNTU20.04 環境での転移学習
YOLO-v3 学習済みモデルを用いる転移学習は、PyTorchフレーム・ワークを使用するケースが多いが、もう一つのTensorFlowフレーム・ワークを使用する転移学習も可能である。ここでは、2つのフレーム・ワークを使用した転移学習をUBUNTO 20.04 環境で実現する場合の手順を述べる事にする。
(1) TensorFlow ver.2フレームワーク下でYOLOv3による転移学習を実現する手順:
TensorFlow ver.1のフレームワーク下で yolov1 や yolov2 による転移学習について述べているサイトもあるが、TensorFlow ver.1は古すぎるので敢えて話題にしない。参考文献(1)は、TensorFlow ver.2でyolov3の学習済みモデルを使用する転移学習を取り上げているサイトである。
① まず、このサイト(https://github.com/zzh8829/yolov3-tf2)に、アクセスしてページの緑色の[Code]をクリックして、Download ZIPファイルをダウンロードする。ダウンロード後、自分のホーム(/home/ユーザー名)下に展開するとディレクトリyolov3-tf2-masterができる。
上記のgithubサイトをターミナルを起動し、ホームをカレント・ディレクトリにして git clone コマンドを実行して、デポジトリ・サイトのクローン化を試みたが、登録ユーザ名とパスワードを要求されてしまい、クローン化は失敗した。上記のgithubサイトの現在は一般ユーザーのクローン化を受け付けなくなっている様である。その為、次善の策としてブラウザで上記のサイトにアクセスし、Download ZIPファイルをダウンロードし、ホームディレクトリの下にyolov3-tf2-masterディレクトリを展開する方法を取った。
② Pythonの仮想環境 py37-tf2pt117 のterminalを開き、下記コマンドを入力してカレント・ディレクトリを yolov3-tf2-master ディレクトリに移動する。
$ cd yolo3-tf2-master
③ yolov3の学習済みモデルと同じpython環境を一括インストールするrequirements.txtファイルを以下のコマンドで実行する。ディレクトリyolov3-tf2-master には 2つの requirements.txtファイルが存在している。即ち、requirements.txtとrequirements-gpu.txt である。
(a) CPUだけの場合、
~/yolov3-tf2-master$ pip install -r reqirements.txt
(b) GPUが利用できる場合、
~/yolov3-tf2-master$ pip install -r reqirements-gpu.txt
この requirements.txtファイル の存在により、学習済みモデルのPython環境と転移学習でのPython環境を試行錯誤によって合わせる必要がなくなった。YOLOv3の利用(1): Mac OS Sierra 環境での転移学習では requirements.txtファイルが存在しなかったのでエラーの解消を試行錯誤により続けざるを得なかった。
④ 次に、学習済みのweightファイルのダウンロードを以下のサイトから行う。
https://pjreddie.com/media/files/yolov3.weights
ダウンロードしたyolov3.weightsファイルはディレクトリyolov3-tf2-master内のdataフォルダ内に配置する必要がある。
⑤ ダウンロードした yolov3.weightsファイルを下記のコマンドによりkerasモデル用に変換を行う。
~/yolov3-tf2-master$ python convert.py –weights data/yolov3.weights –output checkpoints/yolov3.tf
⑥ Fig.1 に示す画像データstreet.jpgをdataフォルダに配置し、

Fig.1. Street.jpg
下記のコマンドを実行する。
~/yolov3-tf2-master$ python detect.py –image data/street.jpg
ディレクトリyolov3-tf2-master内に、画像データstreet.jpg内の対象物の検出領域、枠ラベルと検出精度等が付いた処理済みの画像データoutput.jpg が作成される(Fig.2.参照)。
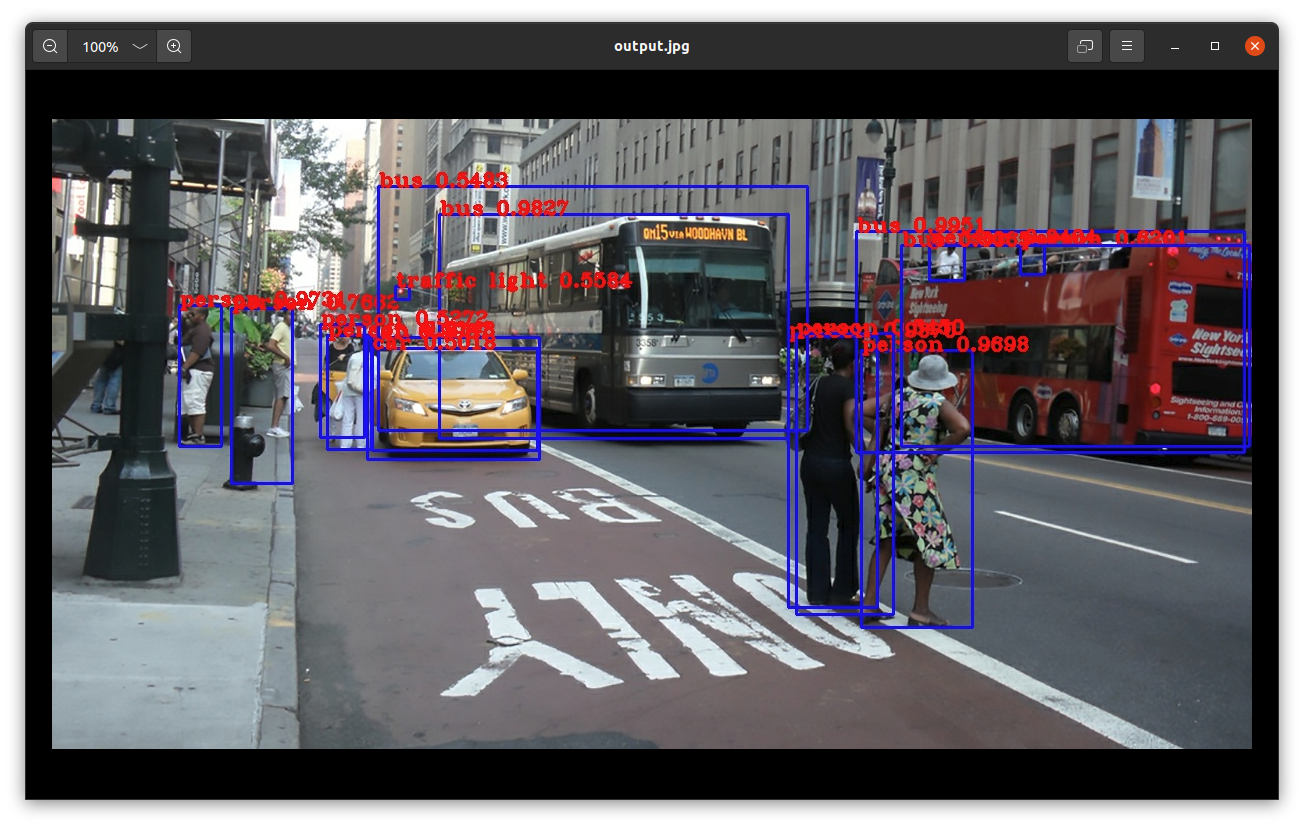
Fig.2. 対象物検出処理済み画像。
⑦ ビデオ映像内の対象物検出の場合:
サンプルビデオcars.mp4をdataフォルダ内に配置し、下記のコマンド実行により、対象物検出処理済みの映像ビデオoutput.aviを制作できる。
~/yolov3-tf2-master>$ python detect_video.py –video data/cars.mp4 –output moving-cars.avi
Fig.3. 対象物検出済みビデオ映像。moving-cars.aviをmoving-cars.mp4に変換して埋め込んでいる。
参考文献(3)によれば、OpenCVは版権の関係から直接的に.mp4ファイルの直接書込み制作をサポートしない。しかし、Ciscoが版権を持っているが、バイナリーファイルopenh264-1.8.0-linux64.4soを同じフォルダ保に配置すれば、オープン使用が認められるとのことである。これに従い、Windows 10では、openh264-1.8.0-win64.dllをMacでは、libopenh264-1.8.0-osx64.4dylibをプログラムと同じフォルダに配置して、下記コマンドの実施により、moving-cars.mp4ファイルを直接書込み出力できた。しかし、Linux(Ubuntu)の場合、libopenh264-1.8.0-linux64.4soをプログラムと同じフォルダに配置して、detect_video.py
の21行目を以下の様にコメントアウトし、
#flags.DEFINE_string(‘output_format’, ‘XVID‘, ‘codec used in VideoWriter when saving video to file’)
22行目に下記の行を挿入
flags.DEFINE_string(‘output_format’, ‘H264‘, ‘codec used in VideoWriter when saving video to file’)
後に、下記のプログラムを実行してもmoving-cars.mp4ファイルは出力されなかった。
> python detect_video.py –video data/cars.mp4 –output moving-cars.mp4
次の(2) PyTorchフレームワーク下の転移学習でも同様にmp4ファイルの制作に失敗するので、LinuxのFFMPEGの何らかの仕様でmp4が作成できないと思われる。
⑧ カメラ映像内の対象物検出の場合:
下記コマンド実行により、USBカメラによるリアルタイム映像に対し、直ちに対象物の検出処理済み映像をoutput.aviとして、書き込み制作できる。
~/yolov3-tf2-master> python detect_video.py –video 0 –output output.avi
いずれの場合も、計算にはNvidia GPUを使用しており、Ubuntu 20.04における転移学習の高速処理の実現を確認できた。
① まず、YOLOv5の転移学習の所で取り上げたPython 仮想環境 py36-tf114pt17 を activate する。その後、ターミナルを立ち上げ、そのホームデレクトリにて、下記の git clone コマンドを実行する。
> git clone https://github.com/nekobean/pytorch_yolov3.git
次に、以下の cd コマンドにより、カレント・デレクトリをpytorch_yulov3に移動する。
> cd pytorch_yolov3
②このクローン・ディレクトリpytorch_yolov3には requirements.txtファイルが存在しており、下記コマンドの実行により、転移学習をするPythonライブラリ環境をyolov3の学習済みモデルのPythonライブラリ環境と合わせることができる。
> pip install -r requirements.txt
③下記のコマンドをターミナルで実行し、MS COCOの学習時の重みファイルをダウンロードする。
./weights/download_weights.sh
これにより、weightsディレクトリ以下に次の2つのファイルがダウンロードされる。
yolov3.weights: MSCOCO で学習した YOLOv3 の重みファイルyolov3-tiny.weights: MSCOCO で学習した YOLOv3-tiny の重みファイル
MS(MicroSoft) COCO の学習済みモデル
yolov3.weights 及び yolov3-tiny.weightsは、以下の80クラスを含む約10万枚の画像で構成される画像データセットで学習した重みファイルである。 この80クラスの対象物を検出する場合は、yolov3の学習済みモデルを利用すれば、すぐ検出を行うことが可能である。
| クラス ID | クラス名 | クラス ID | クラス名 | クラス ID | クラス名 | クラス ID | クラス名 |
|---|---|---|---|---|---|---|---|
| 0 | 人 | 20 | ゾウ | 40 | ワイングラス | 60 | ダイニングテーブル |
| 1 | 自転車 | 21 | クマ | 41 | カップ | 61 | トイレ |
| 2 | 車 | 22 | シマウマ | 42 | フォーク | 62 | テレビ |
| 3 | バイク | 23 | キリン | 43 | ナイフ | 63 | ノートパソコン |
| 4 | 飛行機 | 24 | リュックサック | 44 | スプーン | 64 | マウス |
| 5 | バス | 25 | 傘 | 45 | ボウル | 65 | リモコン |
| 6 | 電車 | 26 | ハンドバッグ | 46 | バナナ | 66 | キーボード |
| 7 | トラック | 27 | ネクタイ | 47 | リンゴ | 67 | 携帯電話 |
| 8 | 船 | 28 | スーツケース | 48 | サンドウィッチ | 68 | 電子レンジ |
| 9 | 信号機 | 29 | フリスビー | 49 | オレンジ | 69 | オーブン |
| 10 | 消火栓 | 30 | スキー | 50 | ブロッコリー | 70 | トースター |
| 11 | ストップサイン | 31 | スノーボード | 51 | キャロット | 71 | シンク |
| 12 | パーキングメーター | 32 | スポーツボール | 52 | ホットドッグ | 72 | 冷蔵庫 |
| 13 | ベンチ | 33 | カイト | 53 | ピザ | 73 | 本 |
| 14 | 鳥 | 34 | 野球バット | 54 | ドーナツ | 74 | 時計 |
| 15 | 猫 | 35 | 野球グラブ | 55 | ケーキ | 75 | 花瓶 |
| 16 | 犬 | 36 | スケートボード | 56 | 椅子 | 76 | ハサミ |
| 17 | 馬 | 37 | サーフボード | 57 | ソファー | 77 | テディベア |
| 18 | 羊 | 38 | テニスラケット | 58 | 鉢植え | 78 | ヘアードライヤー |
| 19 | 牛 | 39 | ボトル | 59 | ベッド | 79 | 歯ブラシ |
Table 1. MS COCOの80クラス検出カテゴリ(表の作成は参考文献(2)による)。
③ フォルダdataに単一画像を配置し、検出処理済み画像をoutputフォルダに出力する場合:
> python detect_image.py –input data/giraffe.png –output output –weights weights/yolov3.weights –config config/yolov3_coco.yaml

Fig.3. キリンとシマウマの画像。
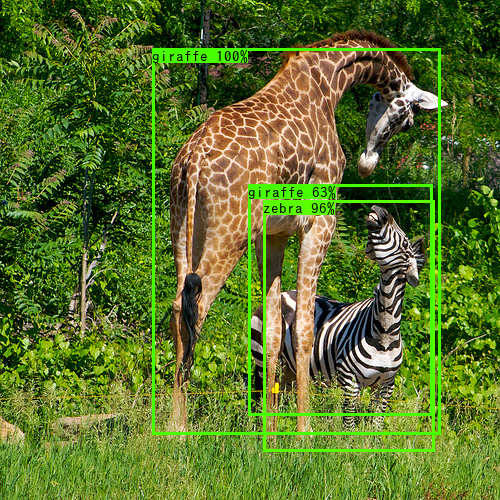
Fig.4. 検出済みのキリンとシマウマの画像。
④フォルダdataに複数の画像を配置し、複数の検出処理画像をoutputフォルダに出力する場合:
> python detect_image.py –input data –output output –weights weights/yolov3.weights –config config/yolov3_coco.yaml
⑤フォルダdataにビデオ映像sample.aviを配置し、検出済み映像をoutputフォルダにoutput.aviとして書き込む場合、下記のコマンドを実行すれば良い:
高速処理のため、yolov3-tiny.weightsとyolov3tiny_coco.yamlを使用し、且つ、gpu_id として0 番を指定している。gpuが1個の場合、その装置番号は0番となる。
> python detect_video.py –input data/sample.avi –output output –weights weights/yolov3-tiny.weights –config config/yolov3tiny_coco.yaml –gpu_id 0
https://github.com/cisco/openh264/releases
49行目のoutput_path = args.output / f”{args.input.stem}.avi“を
output_path = args.output / f”{args.output.stem}.mp4“に変更、
> python detect_video.py –input data/sample.avi –output output –weights weights/yolov3-tiny.weights –config config/yolov3tiny_coco.yaml –gpu_id 0
Windows 10とMacではCiscoの交付サイトからOpenh264のバイナリー・ライブラリを配置すれば、mp4ファイルの書き込みに成功するのに、linux(Ubuntu)ではmp4ファイルの書き込みに失敗することが確認できた。
参考文献
(1) :
(2) YOLOv3 – 学習済みモデルで画像から人や車を検出する方法
https://pystyle.info/pytorch-yolov3-how-to-use-pretrained-model/
(3) OpenCVで作成した動画がブラウザで正常に表示できない場合の解決法
OpenCVで作成した動画がブラウザで正常に表示できない場合の解決法